機械学習 人気本 ランキング
機械学習 新書一覧

本書の内容
オンライン教育プラットフォームUdemyの人気講師が教えるディープラーニングの基礎、第2弾。前作「はじめてのディープラーニング」では、基礎中の基礎であるニューラルネットワークとバックプロパゲーションを初学者にもわかりやすく解説しましたが、本作では自然言語処理の分野で真価を発揮する再起型ニューラルネットワーク(RNN)と、ディープラーニングの生成モデルであるVAE(Variational Autoencoder)とGAN(Generative Adversarial Networks)について実装方法を含めて解説します。もちろんプログラムの実装については、前作を踏襲してPythonのみで行い、既存のフレームワークに頼りません。
[本書の特徴] ・前作を読んでいない方のために、Python、数学、ニューラルネットワークの基礎について解説する章を設けています。 ・サンプルプログラムはフレームワークを使わずにPythonのみで記述しています。このため数式をコード化する際の原理が初心者にもわかりやすくなっています。 ・サンプルプログラムはSBクリエイティブ株式会社のサイトからダウンロード可能です。 ・Python3、Jupyter Notebook、Google Colaboratory対応 第1章 ディープラーニングの発展 ディープラーニングの概要 ディープラーニングの応用 本書で扱う技術 本書の使い方 第2章 学習の準備 Anacondaの環境構築 Google Colaboratoryの使い方 Jupyter Notebookの使い方 Pythonの基礎 NumPyとmatplotlib 数学の基礎 第3章 ディープラーニング基礎 ニューラルネットワーク、ディープラーニングの概要 全結合層の順伝播 全結合層の逆伝播 全結合層の実装 シンプルなディープラーニングの実装 第4章 RNN RNNの概要 RNN層の順伝播 RNN層の逆伝播 RNN層の実装 シンプルなRNNの実装 RNNが抱える問題 第5章 LSTM LSTMの概要 LSTM層の順伝播 LSTM層の逆伝播 LSTM層の実装 シンプルなLSTMの実装 文章の自動生成 第6章 GRU GRUの概要 GRU層の順伝播 GRU層の逆伝播 GRU層の実装 シンプルなGRUの実装 Encoder-Decoder 第7章 VAE VAEの概要 VAEの仕組み オートエンコーダの実装 VAEに必要な層 VAEの実装 VAEの派生技術 第8章 GAN GANの概要 GANの仕組み GANに必要な層 GANの実装 GANの派生技術 |

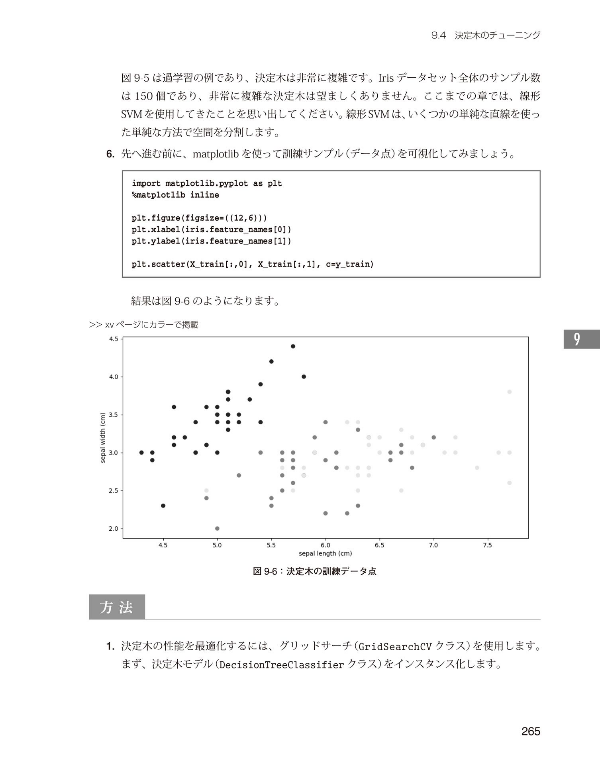
本書の内容機械に学習させる調教師への道 【本書の内容】 本書は「機械が学習する」というテーマのもと、 一般に「ディープラーニング」というと、その背景となる数学的厳密性を全面に押し出し、 Webアプリケーションを開発する際に、フレームワークによってインフラを意識することなく なにはともあれ、最初に提示されるPythonコードを「暗記」してみてください。 【本書のポイント】 【読者が得られること】 ※本電子書籍は同名出版物を底本として作成しました。記載内容は印刷出版当時のものです。 |

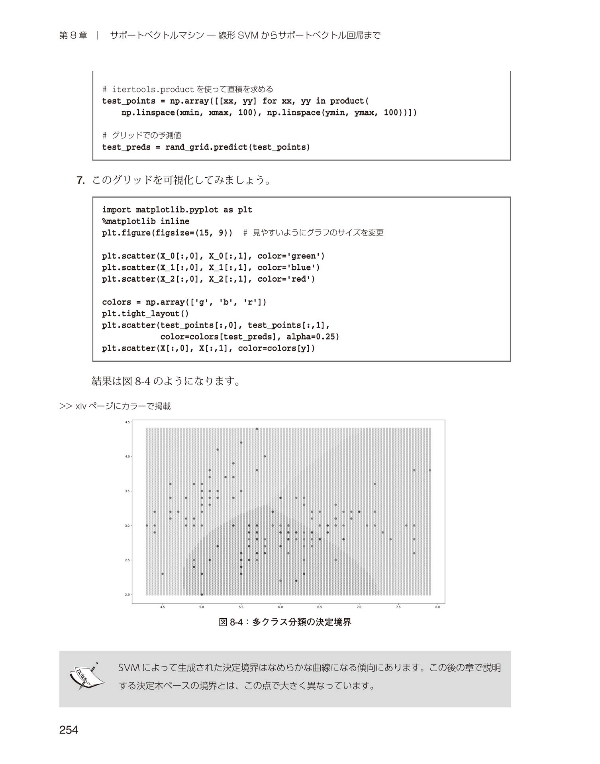
|

本書の内容
第一線のAIエンジニアによる
実プロジェクトの経験に裏打ちされた 「自然言語処理」のツボをここに集約! 【本書の目的】 本書は、Pythonを利用して、人工知能分野で注目されている 自然言語の分析手法を解説した書籍です。 従来技術と新技術を比較しつつ、 「インデックス化」「エンティティ抽出」「関係抽出」 「構文解析」「評価・感情・概念分析」を網羅。 Pythonによるプログラムや、APIの利用、 商用サービス(IBM Watson)や OSS(Mecab/Elasticsearch/Word2Vec)の利用など、 実践的な手法を解説します。 また最終章で話題のBERTについて解説します。 【本書の特徴】 本書は全体で5章構成になっています。 第1章:テキスト分析の概要をユーザ―目線、エンジニア目線の両方から丁寧に解説します。 第2章:テキスト分析のタスクを上げ、実際の分析までの具体的な方法を解説します。 第3章:AIの発達する前から利用されていたテキスト分析の手法について、 MecabやElasticsearchといったOSSを利用して解説します。 第4章:IBM社のWatson APIのAI技術を利用したテキスト分析手法を解説します。 第5章:Word2VecというOSSを利用した分析手法や、話題のBERTについて解説します。 【対象読者】 自然言語処理を学びたい理工学生・エンジニア ※本電子書籍は同名出版物を底本として作成しました。記載内容は印刷出版当時のものです。 ※印刷出版再現のため電子書籍としては不要な情報を含んでいる場合があります。 ※印刷出版とは異なる表記・表現の場合があります。予めご了承ください。 ※プレビューにてお手持ちの電子端末での表示状態をご確認の上、商品をお買い求めください。 |

本書の内容
■内容紹介■
Python / Flask と リクルートの 人工知能 API を使って 雑談 LINE bot を作ります。 Google Colaboratoryを使うので環境構築不要ですぐに始められます。 ■書籍で扱う内容■ ・ Python ・ Flask ・ LINE bot ・ 人工知能 API ・ Heloku ・Google Colaboratory ・ ngrok ■目次■ 0.はじめに 1.Google Colaboratory 1-1.Google Colaboratoryとは 1-2.Google Colaboratoryを使ってみる 2.人工知能APIを使ってみる 2-1.リクルートのA3RT(アート) 2-2.APIキー発行 2-3.実装する 2-4.関数化する 3.LINEボット化する 3-1.LINEボットが動く仕組み 3-2.Flaskでローカルサーバーを立ち上げる 3-3.ngrokでローカルサーバーを外から使えるようにする 3-4.LINEボットを実装 4.Herokuへデプロイする 4-1.Herokuとは 4-2.Herokuに登録 4-3.Heroku CLIのインストールとログイン 4-4.Heroku用のファイルを準備 4-5.Herokuにデプロイ 5.おわりに |

本書の内容
システムトレーダー、エンジニアなどの間で話題沸騰
発売後売り切れの書店続出、大反響につき即増刷決定! 人工知能(AI)、機械学習の発展は金融をどのように変えるのか 理論と実務を熟知した第一人者による比類なき大著“Advance in Financial Machine Learning"(2018年、Wileyより刊行)、待望の日本版刊行! すでに中国語、韓国語、ロシア語にも翻訳された名著を、実務を知り尽くしたクオンツが日本の読者に向けて翻訳 データの構造化とラべリング、モデリング、バックテスト、ハイパフォーマンスコンピューティングなど、金融工学における機械学習の活用の可能性を、Pythonのコード例を交えて徹底解説 目次 はじめに 第1章 ファイナンス機械学習という新分野 Part1 データ分析 第2章 金融データの構造 第3章 ラベリング 第4章 標本の重み付け 第5章 分数次差分をとった特徴量 Part2 モデリング 第6章 アンサンブル法 第7章 ファイナンスにおける交差検証法 第8章 特徴量の重要度 第9章 交差検証法によるハイパーパラメータの調整 Part3 バックテスト 第10章 ベットサイズの決定 第11章 バックテストの危険性 第12章 交差検証によるバックテスト 第13章 人工データのバックテスト 第14章 バックテストの統計値 第15章 戦略リスクを理解する 第16章 機械学習によるアセットアロケーション Part4 金融市場分析のための特徴量 第17章 構造変化 第18章 エントロピー特徴量 第19章 マイクロストラクチャーに基づく特徴量 Part5 ハイパフォーマンスコンピューティング 第20章 マルチプロセッシング(多重処理)とベクトル化 第21章 総当たり法と量子コンピュータ 第22章 ハイパフォーマンス計算知能と予測技術 Kesheng Wu and Horst Simon |

|
本書の内容
AIエキスパートの知見から得る、新たな視点!
理論と現場を橋渡しする、機械学習の実践的エッセンス。 数式をどう読み解くか。 各手法がどこまで活用できるか。 問題をどう乗り越えるか。 米国で大ブレークの機械学習本を翻訳 機械学習アルゴリズムにおける考え方や数式を示し、 アルゴリズムの特徴、利用条件、長所/短所、活用範囲などを解説。 一気に読める量でありながらも、主要な手法を網羅。 著者は、人工知能分野で博士号を取得、その後は企業で実装を続けています。 本書では、そうして積み重ねた知見を展開。 現実問題に取り組むための知識が得られる貴重な一冊です。 数学や統計学、プログラミングについてあまり高度な知識や経験を求めていませんが 取り上げている手法に時間を費して学べる人なら、かなり読み進められるはずです。 機械学習を学ぶ機会を探している初学者にも、 すでに実務に携わっていてより知識を広げたい熟練者にも適しています。 この分野でPh.D論文の研究をこれから始めようという人にはきっと本書が必要で、 研究が進むにつれて有用な参考書となるでしょう。 ◎本書は『The Hundred-Page Machine Learning Book』の翻訳書です。 数学など一定の知識が前提となっています。 ※この商品は固定レイアウトで作成されており、タブレットなど大きいディスプレイを備えた端末で読むことに適しています。また、文字列のハイライトや検索、辞書の参照、引用などの機能が使用できません。 購入前にお使いの端末で無料サンプルをお試しください。 |

|

本書の内容
「Pythonで強化学習が実装できる!」と好評を得た入門書の改訂版。読者からの要望・指摘を反映させた。主に、Policy GradientとA2Cの記述・実装を見直した。・Pythonプログラミングとともに、ゼロからていねいに解説。・コードが公開されているから、すぐ実践できる。・実用でのネックとなる強化学習の弱点と、その克服方法まで紹介。【おもな内容】Day1 強化学習の位置づけを知る 強化学習とさまざまなキーワードの関係 強化学習のメリット・デメリット 強化学習における問題設定:Markov Decision Process Day2 強化学習の解法(1): 環境から計画を立てる 価値の定義と算出: Bellman Equation 動的計画法による状態評価の学習: Value Iteration 動的計画法による戦略の学習: Policy Iteration モデルベースとモデルフリーとの違いDay3 強化学習の解法(2): 経験から計画を立てる 経験の蓄積と活用のバランス: Epsilon-Greedy法 計画の修正を実績から行うか、予測で行うか: Monte Carlo vs Temporal Difference 経験を価値評価、戦略どちらの更新に利用するか:Valueベース vs PolicyベースDay4 強化学習に対するニューラルネットワークの適用 強化学習にニューラルネットワークを適用する 価値評価を、パラメーターを持った関数で実装する:Value Function Approximation 価値評価に深層学習を適用する:Deep Q-Network 戦略を、パラメーターを持った関数で実装する:Policy Gradient 戦略に深層学習を適用する:Advantage Actor Critic (A2C) 価値評価か、戦略かDay5 強化学習の弱点 サンプル効率が悪い 局所最適な行動に陥る、過学習をすることが多い 再現性が低い 弱点を前提とした対応策Day6 強化学習の弱点を克服するための手法 サンプル効率の悪さへの対応: モデルベースとの併用/表現学習 再現性の低さへの対応: 進化戦略 局所最適な行動/過学習への対応: 模倣学習/逆強化学習Day7 強化学習の活用領域 行動の最適化 学習の最適化
|
本書の内容ディープラーニングを学ぶなら、「仕組み」も「プログラム」もしっかり解説している本書から! |

|

本書の内容
※このKindle本はプリント・レプリカ形式で、Kindle Paperwhiteなどの電子書籍リーダーおよびKindle Cloud Readerではご利用いただけません。Fireなどの大きいディスプレイを備えたタブレット端末や、Kindle無料アプリ (Kindle for iOS、Kindle for Android、Kindle for PC、Kindle for Mac) でのみご利用可能です。また、文字列のハイライト、検索、辞書の参照、引用については、一部機能しない場合があります。文字だけを拡大することはできません。
※プリント・レプリカ形式は見開き表示ができません。 ※この電子書籍は紙版書籍のページデザインで制作した固定レイアウトです。 本当にPythonでデータマイニングと機械学習を行いたい人のための入門書 本書は,本当にPythonでデータマイニングと機械学習を行いたい人のための入門書です. 初歩からていねいに解説してあります. 本書を読み切れば,誰でもPythonによるデータマイニングと機械学習の主な手法の実装方法が身に付きます。 準備編 第1章 データマイニングと機械学習 第2章 Python速習(基本編) 第3章 Python 速習(応用編) 基礎編 第4章 回帰分析 第5章 階層型クラスタリング 第6章 非階層型クラスタリング 第7章 単純ベイズ法による分類 第8章 サポートベクトルマシン法による分類 実践編 第9章 時系列数値データの予測 第10章 日経平均株価の予測 第11章 テキストデータマイニング 第12章 Wikipedia記事の類似度 第13章 画像データの取り扱い手法 第14章 画像の類似判別とクラスタリング |

本書の内容
NumPyは、配列計算が高速に行えるPythonの数値計算用ライブラリです。
科学技術分野を中心に人気が高く、数値計算、データ分析、機械学習に欠かせないツールとなっています。 本書ではまず配列の仕組みとその演算をていねいに説明します。続いて、機械学習を理解する上で欠かせない線形代数について、NumPyを使った基本的な演算を行います。 これらの準備の後で、実データを使ったデータ分析で機械学習の基礎を学びます。 さらにNumPyと一緒によく使われるSciPy、pandas、scikit-learnなどのライブラリとの関係を示して、いくつかの例を紹介します。 最後に扱うのは効率化の追求です。 本書は、NumPyとそれに関連するPythonの配列と演算についての知識とスキルをコンパクトにまとめているので、NumPyの機能と威力が体感できます。 |

|
本書の内容 |

|
本書の内容
AI開発に必要な数学の基礎知識がこれ1冊でわかる!
【本書の目的】 本書は以下のような対象読者に向けて、 線形代数、確率、統計/微分 といった数学の基礎知識をわかりやすく解説した書籍です。 【対象読者】 数学がAIや機械学習を勉強する際の障壁になっている方 AIをビジネスで扱う必要に迫られた方 数学を改めて学び直したい方 文系の方、非エンジニアの方で数学の知識に自信のない方 コードを書きながら数学を学びたい方 【目次】 序章 イントロダクション 第1章 学習の準備をしよう 第2章 Pythonの基礎 第3章 数学の基礎 第4章 線形代数 第5章 微分 第6章 確率・統計 第7章 数学を機械学習で実践 Appendix さらに学びたい方のために |

|

|

本書の内容
(概要)
機械学習・ディープラーニングについて学ぶための、図解形式の解説書です。エンジニア1年生、機械学習関連企業への就職・転職を考えている人が、機械学習・ディープラーニングの基本と関連する技術、しくみ、開発の基礎知識などを一通り学ぶことができます。 (こんな方におすすめ) ・機械学習・ディープラーニングの基本を知りたい人 (目次) 1章 人工知能の基礎知識2章 機械学習の基礎知識3章 機械学習のプロセスとコア技術4章 機械学習のアルゴリズム5章 ディープラーニングの基礎知識6章 ディープラーニングのプロセスとコア技術7章 ディープラーニングのアルゴリズム8章 システム開発と開発環境 |

|

|

|

本書の内容
※この商品は固定レイアウト型の電子書籍です。
※この商品はタブレットなど大きいディスプレイを備えた端末で読むことに適しています。また、文字列のハイライトや検索、辞書の参照、引用などの機能が使用できません。 ※お使いの端末で無料サンプルをお試しいただいた上でのご購入をお願いいたします。 ※本書内容はカラー(2色)で制作されているため、カラー表示可能な端末での閲覧を推奨いたします。 数学がニガテでも大丈夫! 今度はディープラーニングをやさしく学ぼう 「ディープラーニングをライブラリで実装できるけれど、よく意味が分かっていない」 「ディープラーニングの背景にある数式を理解して、何が行われているか知っておきたい」 本書はそんな人のための本です。 勉強中のプログラマ「アヤノ」と、友達の「ミオ」の会話を通じて、ディープラーニングでどんなふうに入力値から出力値までの計算がされているのか、楽しく学んでいきます。 ※本書は『やさしく学ぶ 機械学習を理解するための数学のきほん』の続刊となりますが、前作を読んでいない人でも問題なく読むことができます。 本書では、 ・ニューラルネットワークでは何ができるのか ・単層のパーセプトロンではどのような計算が行われているのか ・パーセプトロンではどうやって問題を解いているのか ・パーセプトロンにはどんな欠点があるのか などの基本的な部分から解説を始めます。 パーセプトロンが理解できたら、続いて多層のニューラルネットワークについて学んでいきます。 ・ニューラルネットワークではどうやって問題を解いているのか ・問題を正しく解くためのパラメーターはどうやって学習しているのか といったことについて、1つずつ数式を理解して、時には具体的な数値を当てはめて実際に計算しながら理解していきます。 ニューラルネットワークが理解できたら、いよいよ画像の分類などに向いている「畳み込みニューラルネットワーク」について学習を進めます。 何をやっているのか、図解と数式で確認しつつ学習し、どのようにして「畳み込みニューラルネットワーク」が分類のタスクを行っているのか丁寧に解説します。 そして最後の章では、ここまでの章で学習した数式をもとに、Pythonでプログラムを書いていきます。ライブラリとしてはNumPyだけを使用し、学習した数式を振り返りながらプログラムを書いていきます。ディープラーニング用のライブラリでは数行で書ける部分ですが、1行1行理解しながら動かしていくことで、理解を深めることができます。 【各章の概要】 Chapter1 ニューラルネットワークを始めよう ニューラルネットワークがどんな構造をしていて、どういうことができるのかについて、図や簡単な数式を使って解説します。 Chapter2 順伝播を学ぼう パーセプトロンというニューラルネットワークを構成する小さなアルゴリズムについて、どんな風に計算が行われるかを解説します。 Chapter3 逆伝播を学ぼう ニューラルネットワークで、適切な重みとバイアスをどのように計算して求めればよいかについて説明します。 Chapter4 畳み込みニューラルネットワークを学ぼう 畳み込みニューラルネットワーク特有の仕組みや計算を取り上げながら、重みとバイアスの更新方法まで説明します。 Chapter5 ニューラルネットワークを実装しよう ここまでの章で学んだニューラルネットワークの計算方法を踏まえ、Pythonでプログラミングしていきます。 Appendix Chapter1からChapter5までには入りきらなかった数学の知識と、環境構築、PythonとNumPyの簡単な説明を入れています。 総和の記号/微分/偏微分/合成関数/ベクトルと行列/指数・対数/Python環境構築/Pythonの基本/NumPyの基本 ●著者 立石 賢吾(たていし けんご) スマートニュース株式会社 機械学習エンジニア。 佐賀大学卒業後にいくつかの開発会社を経て、2014年にLINE Fukuoka株式会社へ入社。同社にてデータ分析及び機械学習を専門とする組織を福岡で立ち上げ、レコメンドやテキスト分類など機械学習を使ったプロダクトを担当。同組織の室長を経て2019年にスマートニュース株式会社へ入社、以後機械学習エンジニアとして現職に従事。 |

|

|

本書の内容
※この商品は固定レイアウト型の電子書籍です。
※この商品はタブレットなど大きいディスプレイを備えた端末で読むことに適しています。また、文字列のハイライトや検索、辞書の参照、引用などの機能が使用できません。 ※お使いの端末で無料サンプルをお試しいただいた上でのご購入をお願いいたします。 ※本書内容はカラーで制作されているページがございますため、カラー表示可能な端末での閲覧を推奨いたします。 ディープラーニングの発展・応用手法を実装しながら学ぼう 本書ではディープラーニングの発展・応用手法を実装しながら学習していきます。ディープラーニングの実装パッケージとしてPyTorchを利用します。扱うタスク内容とディープラーニングモデルは次の通りで「ビジネスの現場でディープラーニングを活用するためにも実装経験を積んでおきたいタスク」という観点で選定しました。 [本書で学習できるタスク] 転移学習、ファインチューニング:少量の画像データからディープラーニングモデルを構築 物体検出(SSD):画像のどこに何が映っているのかを検出 セマンティックセグメンテーション(PSPNet):ピクセルレベルで画像内の物体を検出 姿勢推定(OpenPose):人物を検出し人体の各部位を同定しリンク GAN(DCGAN、Self-Attention GAN):現実に存在するような画像を生成 異常検知(AnoGAN、Efficient GAN):正常画像のみからGANで異常画像を検出 自然言語処理(Transformer、BERT):テキストデータの感情分析を実施 動画分類(3DCNN、ECO):人物動作の動画データをクラス分類 本書は第1章から順番に様々なタスクに対するディープラーニングモデルの実装に取り組むことで高度かつ応用的な手法が徐々に身につく構成となっています。各ディープラーニングモデルは執筆時点でState-of-the-Art(最高性能モデル)の土台となっており、実装できるようになればその後の研究・開発に役立つことでしょう。 ディープラーニングの発展・応用手法を楽しく学んでいただければ幸いです。 実装環境 ・読者のPC(GPU環境不要)、AnacondaとJupyter Notebook、AWSを使用したGPUサーバー ・AWSの環境:p2.xlargeインスタンス、Deep Learning AMI(Ubuntu)マシンイメージ(OS Ubuntu 16.04|64ビット、NVIDIA K80 GPU、Python 3.6.5、conda 4.5.2、PyTorch 1.0.1) ●目次 第1章 画像分類と転移学習(VGG) 第2章 物体認識(SSD) 第3章 セマンティックセグメンテーション(PSPNet) 第4章 姿勢推定(OpenPose) 第5章 GANによる画像生成(DCGAN、Self-Attention GAN) 第6章 GANによる異常検知(AnoGAN、Efficient GAN) 第7章 自然言語処理による感情分析(Transformer) 第8章 自然言語処理による感情分析(BERT) 第9章 動画分類(3DCNN、ECO) ●著者 小川 雄太郎 SIerの技術本部・開発技術部に所属。ディープラーニングをはじめとした機械学習関連技術の研究開発・技術支援を業務とする。明石工業高等専門学校、東京大学工学部を経て、東京大学大学院、神保・小谷研究室にて脳機能計測および計算論的神経科学の研究に従事し、2016年に博士号(科学)を取得。東京大学特任研究員を経て、2017年4月より現職。本書の他に、「つくりながら学ぶ! 深層強化学習 -PyTorchによる実践プログラミング-」(マイナビ出版、2018年6月)なども執筆。 |
本書の内容
私たちの日常生活で、人工知能が普通に使われる時代になりました。スマートフォンの顔認証、自動運転技術、SiriやAlexaのようなAI音声アシスタントなど身近な技術ばかりです。これからは機械学習や深層学習はエンジニアの基本教養となるかもしれません。本書は、機械学習や深層学習の分野から画像認識に重点をおいて、難しい数式をつかわず、図や写真を多用して解説する入門書です。必要な概念、用語、キーワードも網羅的に説明します。
※この商品は固定レイアウトで作成されており、タブレットなど大きいディスプレイを備えた端末で読むことに適しています。また、文字列のハイライトや検索、辞書の参照、引用などの機能が使用できません。 |

本書の内容
数学の基礎知識とPythonコードを紐づけて機械学習の基本を学べる!
【本書の目的】 現在、人工知能関連のプロダクト・サービスが数多く見受けられるようになりました。 人工知能関連の開発に機械学習の基礎知識は必須です。 本書はそうした機械学習の基礎知識を学びたいエンジニアに向けた書籍です。 【本書の特徴】 本書は機械学習の基本について、数学の知識をもとに、 実際にPythonでプログラムしながら学ぶことができる書籍です。 ・最新のPython 3.7に対応 ・学習内容を「要点整理」で復習 ・数式とコードをつなげたわかりやすい解説 【読者が得られること】 本書を読み終えた後には、機械学習のしくみとプログラミング手法を理解できます。 【対象読者】 機械学習の基礎を学びたい理工学生・エンジニア 【目次】 第1章機械学習の準備 第2章Pythonの基本 第3章グラフの描画 第4章機械学習に必要な数学の基本 第5章教師あり学習:回帰 第6章教師あり学習:分類 第7章ニューラルネットワーク・ディープラーニング 第8章ニューラルネットワーク・ディープラーニングの応用(手書き数字の認識) 第9章教師なし学習 第10章要点のまとめ |

本書の内容
※この商品はタブレットなど大きいディスプレイを備えた端末で読むことに適しています。また、文字だけを拡大することや、文字列のハイライト、検索、辞書の参照、引用などの機能が使用できません。
人工知能技術の中枢をなす深層学習と物理学との繋がりを俯瞰する。物理学者ならではの視点で原理から応用までを説く、空前の入門書。《目次》第1章 はじめに:機械学習と物理学【第I部 物理から見るディープラーニングの原理】第2章 機械学習の一般論第3章 ニューラルネットワークの基礎第4章 発展的なニューラルネットワーク第5章 サンプリングの必要性と原理第6章 教師なし深層学習【第II部 物理学への応用と展開】第7章 物理学における逆問題第8章 相転移をディープラーニングで見いだせるか第9章 力学系とニューラルネットワーク第10章 スピングラスとニューラルネットワーク第11章 量子多体系、テンソルネットワークとニューラルネットワーク第12章 超弦理論への応用第13章 おわりに |

本書の内容
きれいに整形されたデータを使った分析の経験はあっても、「実務で扱う生データをどのように前処理すればよいのか」と、お悩みではないでしょうか。前処理は課題ごとに、都度オーダーメイドで設計・実装していくものです。本書では4種類のデータを対象とし、機械学習で予測を行う場合の前処理の基本ノウハウを学び、Pythonによる実装を体験します。本書で扱った技術は、そのまま実務にも活かせます。
機械学習における分析モデルの作成は自動化されつつありますが、その時に投入する特徴量は、人の手で前処理して作成する状況が続くでしょう。これからデータ分析に携わる方々にとって、前処理の力を高めることは、きっと大きな助けとなるでしょう。 (本書「あとがき」から抜粋・編集) ■著者プロフィール 足立 悠(あだち はるか) BULB株式会社所属のデータサイエンティスト。 過去にメーカーのSE やデータサイエンティスト、IT ベンダーのデータアナリスト等を経て現職。数々のデータ分析プロジェクトのほか、実務者教育にも従事。個人的な活動として、記事や書籍の執筆、セミナー講師なども行っている。著書に『初めてのTensorFlow』と『ソニー開発のNeural Network Console 入門』がある。 多感な時期に高専で5年間を過ごしてしまったせいか、周囲から変人や外れ値と評されている。趣味はお地蔵さんが密集している場所に佇むこと。近いうちに、日本を北から南へ移動しながら仕事し、パフォーマンスを測定してみたい。 |
本書の内容
近年、企業が円滑にビジネスを進める上で取り扱うデータ量は急増し、本格的なビッグデータ時代の到来がさけばれています。それに伴い、これらビックデータを分析しビジネスに活用するデータサイエンティストの需要も高まっており、各企業では、データサイエンティストの育成に力を入れたり、高額な給与で採用したりと、人材不足に対応する動きが盛んになってきています。
データサイエンティストに欠かせないスキルの1つが、データ分析、ディープラーニング、機械学習などに必要となるプログラミングのスキルです。その中でも、Python(パイソン)に関する知識は必要不可欠となります。 Python(パイソン)は、直観的で非常にわかりやすいプログラミング言語で、シンプルに記述することができ、初心者でも大変学びやすい言語です。 また、たくさんのライブラリと呼ばれる再利用可能なプログラムが公開されていて、これらのライブラリを使って、比較的簡単に高度な機能を実現することができます。AIに関連するライブラリも数多くあり、機械学習、ディーブラーニングやデータ分析の分野でも広く使われています。 Pythonの開発環境だけで無く、これらの非常に便利なライブラリがインターネット上で無料で提供されており、費用をかけずに始めることができます。 この本では、今後データサイエンスや機械学習、AIを学習していきたいと考えている方へ向けて、それらの知識の習得に欠かせないPythonの基本的なトピックに重点を絞り、チュートリアル形式で解説していきます。プログラミング未経験者や初心者でもわかりやすいよう、丁寧に解説していきます。特にPythonでデータ分析・AI・機械学習を学ぶ上で欠かせない基礎となる重要な事項を取り上げています。 【 目次 】 第1章. 環境準備 この章では、Pythonを始めるにあたって欠かすことのできない、環境構築の方法について、初心者でもわかりやすいよう、1つ1つの手順を追って、丁寧に説明しています。是非この記事を元にPythonの開発環境を準備し、プログラミングにチャレンジしてください。 第2章. 基本操作 第1章で準備した開発環境について、今後の章の理解に必要となる基本的な操作の説明をしています。 第3章. 変数 最初に基本となるPythonの変数の宣言や変数名のルールを説明しています。変数とは何か?という説明から、具体的な例を用いて使い方の説明など、初心者にもわかりやすいよう丁寧な解説を心がけています。 第4章. データ型 次にPythonに用意されているデータ型の種類とその確認方法を説明しています。 第5章. 数値計算(四則演算) Pythonでは、数値は四則演算を行うことができるように演算子が用意されています。Pythonに用意されている基本的な四則演算を行うための演算子を確認していきましょう。 第6章. Print関数 画面にメッセージを表示したり、記述したプログラムが正常に動作するか確認する際に、変数などに格納された値を画面に出力するのに必要なprint関数についての解説です。 第7章. リスト(List) Pythonにおけるリスト(配列)の使い方に関する記事です。リストとは何か?その特徴は?という基本的な説明から始まり、リストへの要素の追加の方法や、追加した要素の変更、削除方法、また検索方法について説明しています。 第8章. タプル(Tuple) タプルは読み取り専用のリストのようなものです。タプルについても定義の仕方や検索方法について解説していきます。 第9章. ディクショナリ(Dictionary) Pythonには、キーと紐付けて値を登録することで、取り出しやすいかたちでデータを格納することができるDictionary(辞書)というものがあり、特徴や使い方を取り上げています。 第10章. 条件分岐(IF文) この章では、Pythonにおける条件分岐(If文)の記述方法や注意点について見ていきます。 第11章. 繰り返し処理(For文) Pythonの繰り返し処理の1つであるFor文の書き方や使い方の例を取り上げています。 第12章. 繰り返し処理(While文) Pythonの繰り返し処理にはWhile文もあり、For文との違いやWhile文の使い方を説明しています。 第13章. コメント プログラムに関する注釈であるコメントについての書き方や、規約・ルールの例、便利な表示方法について解説しています。 第14章. 関数 何度も繰り返し利用する処理は、関数と呼ばれる一連の命令として定義しておくと、同じコードを記述する必要が無く、関数を呼び出すだけで良いので非常に便利です。ここでは、関数の記述方法や呼び出し方について説明しています。 第15章. モジュール、パッケージ、ライブラリ Pythonでは、科学技術計算でよく使われるNumPy(ナンパイ)やグラフ描画に使われるMatplotlib(マットプロットリブ)、データ解析を支援する機能を提供するPandas(パンダス)など、多くの便利な機能がライブラリという形で提供されます。これらのインストール方法や利用するのに必要な基礎知識について説明しています。 第16章. NumPyでベクトル・行列計算 NumPy(ナンパイ)は、ベクトルや行列などを効率的に数値計算するための数学関数ライブラリを提供します。ここでは次のようなトピックについて解説していきます。 ・NumPyでのベクトル、行列の作成方法 ・連続した配列の自動作成 ・ランダムな数値を含む配列の自動作成 ・NumPyでの行列の計算方法 ・NumPyでの配列のインデックス ・NumPyでの配列の更新 ・NumPyの数値計算用関数 ・whereで条件に応じたデータを抽出 ・NumPyでのファイル操作関数 第17章. Matplotlibでグラフの描画 Pythonのグラフの描画に欠かせないのが、Matplotlib(マットプロットリブ)になります。Matplotlibは、Pythonのグラフ描画用ライブラリで、様々なグラフを作成し、データを可視化することができます。この章では、Matplotlibで折れ線グラフ、棒グラフ、円グラフ、散布図など各種グラフの描画方法を解説していきます。 第18章. Pandasでデータ分析 Pandas(パンダス)とは、データを効率的に扱うために開発されたPythonのライブラリの1つで、データ分析、機械学習、ディープラーニングには必要不可欠なものになります。ここでは次のようなトピックについて説明していきます。 ・Seriesの基本(作成、参照、要素の追加、削除、インデックスなど) ・DataFrameの基本(作成、参照、要素の追加、削除、インデックスなど) ・DataFrameへのインデックス追加と削除 ・DataFrameのソート(インデックス、列名、指定した値) ・DataFrameの参照(単一インデックス) ・DataFrameの参照(階層型インデックス) ・DataFrameから条件指定でのデータ抽出 ・Excel、CSVファイルの読み込み、書き込み ・DataFrameの結合(Union) ・DataFrameの結合(Join) ・ピボットテーブルの作成 ・時系列データの分析 [文字数 / ページ数] 約60,250 / 約310ページ [著者紹介] 清水 義孝 (しみず・よしたか) データサイエンティスト 1973年生まれ。 小学生の頃からプログラミングに興味を持ち、MSXでベーシックを習得し、ゲームの自作に夢中になる。 大学卒業後は、某大手IT企業でシステムエンジニアとして、数々のデータウェアハウス、データ分析基盤の導入に携わる。その中で、データ分析に興味を持ち始め、データ分析には、ITの知識、スキルだけでなく、ビジネスに関する深い知識やスキルが必要だと感じる。 論理・仮説思考力、統計・定量分析、プレゼンなどのスキル、ファイナンス・マーケティングなどのビジネスの知識を習得すべく、海外のビジネススクールに通いMBA(経営学修士)取得。 その後、某大手製造業でデータサイエンティストとして、ビックデータの分析に携わる。 データ分析、プログラミングに関して、初心者に役立つ情報を発信すべく、2018年よりWebサイト「Pythonで学ぶデータ分析・AI・機械学習」( https://ai-inter1.com/ )の運営を始める。 |

|

本書の内容
◇-------------------------------------------◇
実践的な基礎が学習しやすい!! ◇-------------------------------------------◇ 注目を集めるPython(パイソン)を使った機械学習の、 実践的な基礎が学べる解説書です。 小さいサンプルプログラム(bot)に機能を追加しながら データ収集から前処理、学習、予測、評価まで 周辺技術も含めた機械学習の全体像が学べます。 本書のサンプルプログラムは、 すべて本書のサポートページからダウンロードできます。 ■本書はこんな人におすすめ ・Pythonの入門書を読み終えた人 ・Pythonを使った機械学習に触れてみたい人 ・業務で役立つ実践的なノウハウが知りたい人 など ■本書の内容 Chapter 1 機械学習について知ろう Chapter 2 環境を準備しよう Chapter 3 スクレイピングでデータ収集をしよう Chapter 4 日本語の文章生成をしよう Chapter 5 手書き文字認識をしよう Chapter 6 データの前処理を学ぼう Chapter 7 回帰分析をしよう Chapter 8 機械学習の次のステップ |
本書の内容
よくわかるPython3入門④Pandasでデータ分析編 - データ分析・機械学習に欠かせない基本をマスターしよう
本書は「よくわかるPython3入門」シリーズの第4弾で、ビジネスにおけるデータ分析によく使われるPandasというライブラリを解説したものになります。 「よくわかるPython3入門」シリーズの第1弾の基礎編をまだご覧になられておられない方は、そちらから始められることをお勧めします。 http://www.amazon.co.jp/dp/B07SRLDGGR 近年、企業が円滑にビジネスを進める上で取り扱うデータ量は急増し、本格的なビッグデータ時代の到来がさけばれています。それに伴い、これらビックデータを分析しビジネスに活用するデータサイエンティストの需要も高まっており、各企業では、データサイエンティストの育成に力を入れたり、高額な給与で採用したりと、人材不足に対応する動きが盛んになってきています。 データサイエンティストに欠かせないスキルの1つが、データ分析、ディープラーニング、機械学習などに必要となるプログラミングのスキルです。その中でも、Python(パイソン)に関する知識は必要不可欠となります。 Python(パイソン)は、直観的で非常にわかりやすいプログラミング言語で、シンプルに記述することができ、初心者でも大変学びやすい言語です。 また、たくさんのライブラリと呼ばれる再利用可能なプログラムが公開されていて、これらのライブラリを使って、比較的簡単に高度な機能を実現することができます。AIに関連するライブラリも数多くあり、機械学習、ディーブラーニングやデータ分析の分野でも広く使われています。 Pythonの開発環境だけで無く、これらの非常に便利なライブラリがインターネット上で無料で提供されており、費用をかけずに始めることができます。 この本では、今後データサイエンスや機械学習、AIを学習していきたいと考えている方へ向けて、それらの知識の習得に欠かせないPythonの基本的なトピックに重点を絞り、チュートリアル形式で解説していきます。プログラミング未経験者や初心者でもわかりやすいよう、丁寧に解説していきます。特にPythonでデータ分析・AI・機械学習を学ぶ上で欠かせない基礎となる重要な事項を取り上げています。 【 目次 】 第1章. 環境準備 この章では、Pythonを始めるにあたって欠かすことのできない、環境構築の方法について、初心者でもわかりやすいよう、1つ1つの手順を追って、丁寧に説明しています。是非この記事を元にPythonの開発環境を準備し、プログラミングにチャレンジしてください。 第2章. 基本操作 第1章で準備した開発環境について、今後の章の理解に必要となる基本的な操作の説明をしています。 第3章. Pandasでデータ分析 Pandas(パンダス)とは、データを効率的に扱うために開発されたPythonのライブラリの1つで、データ分析、機械学習、ディープラーニングには必要不可欠なものになります。ここでは次のようなトピックについて説明していきます。 ・Seriesの基本(作成、参照、要素の追加、削除、インデックスなど) ・DataFrameの基本(作成、参照、要素の追加、削除、インデックスなど) ・DataFrameへのインデックス追加と削除 ・DataFrameのソート(インデックス、列名、指定した値) ・DataFrameの参照(単一インデックス) ・DataFrameの参照(階層型インデックス) ・DataFrameから条件指定でのデータ抽出 ・Excel、CSVファイルの読み込み、書き込み ・DataFrameの結合(Union) ・DataFrameの結合(Join) ・ピボットテーブルの作成 ・時系列データの分析 [文字数 / ページ数] 約29,700 / 約170ページ [著者紹介] 清水 義孝 (しみず・よしたか) データサイエンティスト 1973年生まれ。 小学生の頃からプログラミングに興味を持ち、MSXでベーシックを習得し、ゲームの自作に夢中になる。 大学卒業後は、某大手IT企業でシステムエンジニアとして、数々のデータウェアハウス、データ分析基盤の導入に携わる。その中で、データ分析に興味を持ち始め、データ分析には、ITの知識、スキルだけでなく、ビジネスに関する深い知識やスキルが必要だと感じる。 論理・仮説思考力、統計・定量分析、プレゼンなどのスキル、ファイナンス・マーケティングなどのビジネスの知識を習得すべく、海外のビジネススクールに通いMBA(経営学修士)取得。 その後、某大手製造業でデータサイエンティストとして、ビックデータの分析に携わる。 データ分析、プログラミングに関して、初心者に役立つ情報を発信すべく、2018年よりWebサイト「Pythonで学ぶデータ分析・AI・機械学習」( https://ai-inter1.com/ )の運営を始める。 |

本書の内容
よくわかるPython3入門⑤総集編 - データ分析・機械学習に欠かせない基本をマスターしよう
本書は「よくわかるPython3入門」シリーズの第5弾で、第1弾から第4弾の内容を全て合わせたものとなります。 第1弾で解説したPythonの基礎と合わせて、科学技術計算でよく使われるNumPy(ナンパイ)やグラフ描画に使われるMatplotlib(マットプロットリブ)というライブラリ、さらにデータ分析によく用いられるPandas(パンダス)というライブラリを解説したものになります。 近年、企業が円滑にビジネスを進める上で取り扱うデータ量は急増し、本格的なビッグデータ時代の到来がさけばれています。それに伴い、これらビックデータを分析しビジネスに活用するデータサイエンティストの需要も高まっており、各企業では、データサイエンティストの育成に力を入れたり、高額な給与で採用したりと、人材不足に対応する動きが盛んになってきています。 データサイエンティストに欠かせないスキルの1つが、データ分析、ディープラーニング、機械学習などに必要となるプログラミングのスキルです。その中でも、Python(パイソン)に関する知識は必要不可欠となります。 Python(パイソン)は、直観的で非常にわかりやすいプログラミング言語で、シンプルに記述することができ、初心者でも大変学びやすい言語です。 また、たくさんのライブラリと呼ばれる再利用可能なプログラムが公開されていて、これらのライブラリを使って、比較的簡単に高度な機能を実現することができます。AIに関連するライブラリも数多くあり、機械学習、ディーブラーニングやデータ分析の分野でも広く使われています。 Pythonの開発環境だけで無く、これらの非常に便利なライブラリがインターネット上で無料で提供されており、費用をかけずに始めることができます。 この本では、今後データサイエンスや機械学習、AIを学習していきたいと考えている方へ向けて、それらの知識の習得に欠かせないPythonの基本的なトピックに重点を絞り、チュートリアル形式で解説していきます。プログラミング未経験者や初心者でもわかりやすいよう、丁寧に解説していきます。特にPythonでデータ分析・AI・機械学習を学ぶ上で欠かせない基礎となる重要な事項を取り上げています。 【 目次 】 第1章. 環境準備 この章では、Pythonを始めるにあたって欠かすことのできない、環境構築の方法について、初心者でもわかりやすいよう、1つ1つの手順を追って、丁寧に説明しています。是非この記事を元にPythonの開発環境を準備し、プログラミングにチャレンジしてください。 第2章. 基本操作 第1章で準備した開発環境について、今後の章の理解に必要となる基本的な操作の説明をしています。 第3章. 変数 最初に基本となるPythonの変数の宣言や変数名のルールを説明しています。変数とは何か?という説明から、具体的な例を用いて使い方の説明など、初心者にもわかりやすいよう丁寧な解説を心がけています。 第4章. データ型 次にPythonに用意されているデータ型の種類とその確認方法を説明しています。 第5章. 数値計算(四則演算) Pythonでは、数値は四則演算を行うことができるように演算子が用意されています。Pythonに用意されている基本的な四則演算を行うための演算子を確認していきましょう。 第6章. Print関数 画面にメッセージを表示したり、記述したプログラムが正常に動作するか確認する際に、変数などに格納された値を画面に出力するのに必要なprint関数についての解説です。 第7章. リスト(List) Pythonにおけるリスト(配列)の使い方に関する記事です。リストとは何か?その特徴は?という基本的な説明から始まり、リストへの要素の追加の方法や、追加した要素の変更、削除方法、また検索方法について説明しています。 第8章. タプル(Tuple) タプルは読み取り専用のリストのようなものです。タプルについても定義の仕方や検索方法について解説していきます。 第9章. ディクショナリ(Dictionary) Pythonには、キーと紐付けて値を登録することで、取り出しやすいかたちでデータを格納することができるDictionary(辞書)というものがあり、特徴や使い方を取り上げています。 第10章. 条件分岐(IF文) この章では、Pythonにおける条件分岐(If文)の記述方法や注意点について見ていきます。 第11章. 繰り返し処理(For文) Pythonの繰り返し処理の1つであるFor文の書き方や使い方の例を取り上げています。 第12章. 繰り返し処理(While文) Pythonの繰り返し処理にはWhile文もあり、For文との違いやWhile文の使い方を説明しています。 第13章. コメント プログラムに関する注釈であるコメントについての書き方や、規約・ルールの例、便利な表示方法について解説しています。 第14章. 関数 何度も繰り返し利用する処理は、関数と呼ばれる一連の命令として定義しておくと、同じコードを記述する必要が無く、関数を呼び出すだけで良いので非常に便利です。ここでは、関数の記述方法や呼び出し方について説明しています。 第15章. モジュール、パッケージ、ライブラリ Pythonでは、科学技術計算でよく使われるNumPy(ナンパイ)やグラフ描画に使われるMatplotlib(マットプロットリブ)、データ解析を支援する機能を提供するPandas(パンダス)など、多くの便利な機能がライブラリという形で提供されます。これらのインストール方法や利用するのに必要な基礎知識について説明しています。 第16章. NumPyでベクトル・行列計算 NumPy(ナンパイ)は、ベクトルや行列などを効率的に数値計算するための数学関数ライブラリを提供します。ここでは次のようなトピックについて解説していきます。 ・NumPyでのベクトル、行列の作成方法 ・連続した配列の自動作成 ・ランダムな数値を含む配列の自動作成 ・NumPyでの行列の計算方法 ・NumPyでの配列のインデックス ・NumPyでの配列の更新 ・NumPyの数値計算用関数 ・whereで条件に応じたデータを抽出 ・NumPyでのファイル操作関数 第17章. Matplotlibでグラフの描画 Pythonのグラフの描画に欠かせないのが、Matplotlib(マットプロットリブ)になります。Matplotlibは、Pythonのグラフ描画用ライブラリで、様々なグラフを作成し、データを可視化することができます。この章では、Matplotlibで折れ線グラフ、棒グラフ、円グラフ、散布図など各種グラフの描画方法を解説していきます。 第18章. Pandasでデータ分析 Pandas(パンダス)とは、データを効率的に扱うために開発されたPythonのライブラリの1つで、データ分析、機械学習、ディープラーニングには必要不可欠なものになります。ここでは次のようなトピックについて説明していきます。 ・Seriesの基本(作成、参照、要素の追加、削除、インデックスなど) ・DataFrameの基本(作成、参照、要素の追加、削除、インデックスなど) ・DataFrameへのインデックス追加と削除 ・DataFrameのソート(インデックス、列名、指定した値) ・DataFrameの参照(単一インデックス) ・DataFrameの参照(階層型インデックス) ・DataFrameから条件指定でのデータ抽出 ・Excel、CSVファイルの読み込み、書き込み ・DataFrameの結合(Union) ・DataFrameの結合(Join) ・ピボットテーブルの作成 ・時系列データの分析 [文字数 / ページ数] 約60,250 / 約310ページ [著者紹介] 清水 義孝 (しみず・よしたか) データサイエンティスト 1973年生まれ。 小学生の頃からプログラミングに興味を持ち、MSXでベーシックを習得し、ゲームの自作に夢中になる。 大学卒業後は、某大手IT企業でシステムエンジニアとして、数々のデータウェアハウス、データ分析基盤の導入に携わる。その中で、データ分析に興味を持ち始め、データ分析には、ITの知識、スキルだけでなく、ビジネスに関する深い知識やスキルが必要だと感じる。 論理・仮説思考力、統計・定量分析、プレゼンなどのスキル、ファイナンス・マーケティングなどのビジネスの知識を習得すべく、海外のビジネススクールに通いMBA(経営学修士)取得。 その後、某大手製造業でデータサイエンティストとして、ビックデータの分析に携わる。 データ分析、プログラミングに関して、初心者に役立つ情報を発信すべく、2018年よりWebサイト「Pythonで学ぶデータ分析・AI・機械学習」( https://ai-inter1.com/ )の運営を始める。 |
本書の内容 |

本書の内容
近年、企業が円滑にビジネスを進める上で取り扱うデータ量は急増し、本格的なビッグデータ時代の到来がさけばれています。それに伴い、これらビックデータを分析しビジネスに活用するデータサイエンティストの需要も高まっており、各企業では、データサイエンティストの育成に力を入れたり、高額な給与で採用したりと、人材不足に対応する動きが盛んになってきています。
データサイエンティストに欠かせないスキルの1つが、データ分析、ディープラーニング、機械学習などに必要となるプログラミングのスキルです。その中でも、Python(パイソン)に関する知識は必要不可欠となります。 Python(パイソン)は、直観的で非常にわかりやすいプログラミング言語で、シンプルに記述することができ、初心者でも大変学びやすい言語です。 また、たくさんのライブラリと呼ばれる再利用可能なプログラムが公開されていて、これらのライブラリを使って、比較的簡単に高度な機能を実現することができます。AIに関連するライブラリも数多くあり、機械学習、ディーブラーニングやデータ分析の分野でも広く使われています。 Pythonの開発環境だけで無く、これらの非常に便利なライブラリがインターネット上で無料で提供されており、費用をかけずに始めることができます。 この本では、今後データサイエンスや機械学習、AIを学習していきたいと考えている方へ向けて、それらの知識の習得に欠かせないPythonの基本的なトピックに重点を絞り、チュートリアル形式で解説していきます。プログラミング未経験者や初心者でもわかりやすいよう、丁寧に解説していきます。特にPythonでデータ分析・AI・機械学習を学ぶ上で欠かせない基礎となる重要な事項を取り上げています。 【 目次 】 第1章. 環境準備 この章では、Pythonを始めるにあたって欠かすことのできない、環境構築の方法について、初心者でもわかりやすいよう、1つ1つの手順を追って、丁寧に説明しています。是非この記事を元にPythonの開発環境を準備し、プログラミングにチャレンジしてください。 第2章. 基本操作 第1章で準備した開発環境について、今後の章の理解に必要となる基本的な操作の説明をしています。 第3章. 変数 最初に基本となるPythonの変数の宣言や変数名のルールを説明しています。変数とは何か?という説明から、具体的な例を用いて使い方の説明など、初心者にもわかりやすいよう丁寧な解説を心がけています。 第4章. データ型 次にPythonに用意されているデータ型の種類とその確認方法を説明しています。 第5章. 数値計算(四則演算) Pythonでは、数値は四則演算を行うことができるように演算子が用意されています。Pythonに用意されている基本的な四則演算を行うための演算子を確認していきましょう。 第6章. Print関数 画面にメッセージを表示したり、記述したプログラムが正常に動作するか確認する際に、変数などに格納された値を画面に出力するのに必要なprint関数についての解説です。 第7章. リスト(List) Pythonにおけるリスト(配列)の使い方に関する記事です。リストとは何か?その特徴は?という基本的な説明から始まり、リストへの要素の追加の方法や、追加した要素の変更、削除方法、また検索方法について説明しています。 第8章. タプル(Tuple) タプルは読み取り専用のリストのようなものです。タプルについても定義の仕方や検索方法について解説していきます。 第9章. ディクショナリ(Dictionary) Pythonには、キーと紐付けて値を登録することで、取り出しやすいかたちでデータを格納することができるDictionary(辞書)というものがあり、特徴や使い方を取り上げています。 第10章. 条件分岐(IF文) この章では、Pythonにおける条件分岐(If文)の記述方法や注意点について見ていきます。 第11章. 繰り返し処理(For文) Pythonの繰り返し処理の1つであるFor文の書き方や使い方の例を取り上げています。 第12章. 繰り返し処理(While文) Pythonの繰り返し処理にはWhile文もあり、For文との違いやWhile文の使い方を説明しています。 第13章. コメント プログラムに関する注釈であるコメントについての書き方や、規約・ルールの例、便利な表示方法について解説しています。 第14章. 関数 何度も繰り返し利用する処理は、関数と呼ばれる一連の命令として定義しておくと、同じコードを記述する必要が無く、関数を呼び出すだけで良いので非常に便利です。ここでは、関数の記述方法や呼び出し方について説明しています。 第15章. モジュール、パッケージ、ライブラリ Pythonでは、科学技術計算でよく使われるNumPy(ナンパイ)やグラフ描画に使われるMatplotlib(マットプロットリブ)、データ解析を支援する機能を提供するPandas(パンダス)など、多くの便利な機能がライブラリという形で提供されます。これらのインストール方法や利用するのに必要な基礎知識について説明しています。 [文字数 / ページ数] 約25,000 / 約140ページ [著者紹介] 清水 義孝 (しみず・よしたか) データサイエンティスト 1973年生まれ。 小学生の頃からプログラミングに興味を持ち、MSXでベーシックを習得し、ゲームの自作に夢中になる。 大学卒業後は、某大手IT企業でシステムエンジニアとして、数々のデータウェアハウス、データ分析基盤の導入に携わる。その中で、データ分析に興味を持ち始め、データ分析には、ITの知識、スキルだけでなく、ビジネスに関する深い知識やスキルが必要だと感じる。 論理・仮説思考力、統計・定量分析、プレゼンなどのスキル、ファイナンス・マーケティングなどのビジネスの知識を習得すべく、海外のビジネススクールに通いMBA(経営学修士)取得。 その後、某大手製造業でデータサイエンティストとして、ビックデータの分析に携わる。 データ分析、プログラミングに関して、初心者に役立つ情報を発信すべく、2018年よりWebサイト「Pythonで学ぶデータ分析・AI・機械学習」( https://ai-inter1.com/ )の運営を始める。 |
本書の内容
本書は「よくわかるPython3入門」シリーズの第2弾で、主に科学技術計算でよく使われるNumPy(ナンパイ)やグラフ描画に使われるMatplotlib(マットプロットリブ)というライブラリを解説したものになります。
「よくわかるPython3入門」シリーズの第1弾の基礎編をまだご覧になられておられない方は、そちらから始められることをお勧めします。 近年、企業が円滑にビジネスを進める上で取り扱うデータ量は急増し、本格的なビッグデータ時代の到来がさけばれています。それに伴い、これらビックデータを分析しビジネスに活用するデータサイエンティストの需要も高まっており、各企業では、データサイエンティストの育成に力を入れたり、高額な給与で採用したりと、人材不足に対応する動きが盛んになってきています。 データサイエンティストに欠かせないスキルの1つが、データ分析、ディープラーニング、機械学習などに必要となるプログラミングのスキルです。その中でも、Python(パイソン)に関する知識は必要不可欠となります。 Python(パイソン)は、直観的で非常にわかりやすいプログラミング言語で、シンプルに記述することができ、初心者でも大変学びやすい言語です。 また、たくさんのライブラリと呼ばれる再利用可能なプログラムが公開されていて、これらのライブラリを使って、比較的簡単に高度な機能を実現することができます。AIに関連するライブラリも数多くあり、機械学習、ディーブラーニングやデータ分析の分野でも広く使われています。 Pythonの開発環境だけで無く、これらの非常に便利なライブラリがインターネット上で無料で提供されており、費用をかけずに始めることができます。 この本では、今後データサイエンスや機械学習、AIを学習していきたいと考えている方へ向けて、それらの知識の習得に欠かせないPythonの基本的なトピックに重点を絞り、チュートリアル形式で解説していきます。プログラミング未経験者や初心者でもわかりやすいよう、丁寧に解説していきます。特にPythonでデータ分析・AI・機械学習を学ぶ上で欠かせない基礎となる重要な事項を取り上げています。 【 目次 】 第1章. 環境準備 この章では、Pythonを始めるにあたって欠かすことのできない、環境構築の方法について、初心者でもわかりやすいよう、1つ1つの手順を追って、丁寧に説明しています。是非この記事を元にPythonの開発環境を準備し、プログラミングにチャレンジしてください。 第2章. 基本操作 第1章で準備した開発環境について、今後の章の理解に必要となる基本的な操作の説明をしています。 第3章. NumPyでベクトル・行列計算 NumPy(ナンパイ)は、ベクトルや行列などを効率的に数値計算するための数学関数ライブラリを提供します。ここでは次のようなトピックについて解説していきます。 ・NumPyでのベクトル、行列の作成方法 ・連続した配列の自動作成 ・ランダムな数値を含む配列の自動作成 ・NumPyでの行列の計算方法 ・NumPyでの配列のインデックス ・NumPyでの配列の更新 ・NumPyの数値計算用関数 ・whereで条件に応じたデータを抽出 ・NumPyでのファイル操作関数 第4章. Matplotlibでグラフの描画 Pythonのグラフの描画に欠かせないのが、Matplotlib(マットプロットリブ)になります。Matplotlibは、Pythonのグラフ描画用ライブラリで、様々なグラフを作成し、データを可視化することができます。この章では、次のトピックを解説していきます。 ・Matplotlibで折れ線グラフの描画 ・Matplotlibで棒グラフの描画・ ・Matplotlibで円グラフの描画 ・Matplotlibで散布図の描画 ・Matplotlibで複数のグラフを並べて表示 [文字数 / ページ数] 約20,500 / 約130ページ [著者紹介] 清水 義孝 (しみず・よしたか) データサイエンティスト 1973年生まれ。 小学生の頃からプログラミングに興味を持ち、MSXでベーシックを習得し、ゲームの自作に夢中になる。 大学卒業後は、某大手IT企業でシステムエンジニアとして、数々のデータウェアハウス、データ分析基盤の導入に携わる。その中で、データ分析に興味を持ち始め、データ分析には、ITの知識、スキルだけでなく、ビジネスに関する深い知識やスキルが必要だと感じる。 論理・仮説思考力、統計・定量分析、プレゼンなどのスキル、ファイナンス・マーケティングなどのビジネスの知識を習得すべく、海外のビジネススクールに通いMBA(経営学修士)取得。 その後、某大手製造業でデータサイエンティストとして、ビックデータの分析に携わる。 データ分析、プログラミングに関して、初心者に役立つ情報を発信すべく、2018年よりWebサイト「Pythonで学ぶデータ分析・AI・機械学習」( https://ai-inter1.com/ )の運営を始める。 |

本書の内容
※このKindle本はプリント・レプリカ形式で、Kindle Paperwhiteなどの電子書籍リーダーおよびKindle Cloud Readerではご利用いただけません。Fireなどの大きいディスプレイを備えたタブレット端末や、Kindle無料アプリ (Kindle for iOS、Kindle for Android、Kindle for PC、Kindle for Mac) でのみご利用可能です。また、文字列のハイライト、検索、辞書の参照、引用については、一部機能しない場合があります。文字だけを拡大することはできません。
※プリント・レプリカ形式は見開き表示ができません。 ※この電子書籍は紙版書籍のページデザインで制作した固定レイアウトです。 ストーリーでPythonと機械学習がわかる!! 『機械学習入門―ボルツマン機械学習から深層学習まで―』、『ベイズ推定入門 モデル選択からベイズ最適化まで』につづく、お妃さまシリーズの第3弾を刊行するものです。Pythonの学習を主軸としたものであり、機械学習を実践したくなった人、およびカジュアルでわかりやすいPython入門本を探している人をターゲットとします。Pythonのコードとコードの説明をイラストでわかりやすく解説します。現在注目されているGAN(敵対的生成ネットワーク)についても解説。 第1章 魔法の鏡との出会い 1-1 不思議な言葉Python語? 1-2 古代文明と魔法の鏡 1-3 深い森の中で 1-4 魔法の儀式 1-5 乱数を発生させる 1-6 結果の図示 1-7 2種類の異なるデータ お妃様の勉強ノート1「2つの種類のデータを用意する」 第2章 機械学習の発見 2-1 ニューラルネットワークの構築 2-2 ニューラルネットワークの学習 2-3 修行の成果を見てみよう 2-4 ニューラルネットワークの限界? お妃様の勉強ノート2「ニューラルネットワークを作る」 第3章 思い出のアヤメ 3-1 アヤメのデータを読み込む 3-2 アヤメのデータを識別しよう 3-3 ニューラルネットワークが目覚めるとき 3-4 非線形変換のせいで硬い? 3-5 学習の停滞期 お妃様の勉強ノート3「アヤメの識別」 第4章 画像データを学んでみよう 4-1 手書き文字認識 4-2 現代の小人たち 4-3 自作魔法をまとめよう 4-4 ファッション識別に挑戦 お妃様の勉強ノート4「自作関数にまとめたニューラルネットワーク」 第5章 未来を予測する 5-1 識別から回帰へ 5-2 どんな非線形変換が良いのか? 5-3 深いニューラルネットワーク 5-4 時系列解析に挑戦 5-5 取引データの予測 お妃様の勉強ノート5「株価予測をするニューラルネットワーク」 第6章 深層学習の秘密 6-1 一般物体認識への挑戦 6-2 畳み込みニューラルネットワーク 6-3 確率勾配法の出番 6-4 さらに深いネットワークを作るために 6-5 汎化性能を引き上げるための工夫 6-6 便利なニューラルネットワークを構築する 6-7 畳み込みニューラルネットワークの逆? お妃様の勉強ノート6「畳み込みニューラルネットワーク」 第7章 敵対的生成ネットワーク 7-1 自分のデータセットを用意する 7-2 偽物を作る生成ネットワーク 7-3 白雪姫との別れ 7-4 お妃様との出会い 王宮の図書館の推薦図書(参考文献) 白雪姫が最後にかけた魔法の言葉 あとがき 索引 |

|

|
本書の内容
本書は「よくわかるPython3入門」シリーズの第3弾で、第1弾と第2弾の内容を合わせたものとなります。
第1弾で解説したPythonの基礎と合わせて、第2弾の科学技術計算でよく使われるNumPy(ナンパイ)やグラフ描画に使われるMatplotlib(マットプロットリブ)というライブラリを解説したものになります。 近年、企業が円滑にビジネスを進める上で取り扱うデータ量は急増し、本格的なビッグデータ時代の到来がさけばれています。それに伴い、これらビックデータを分析しビジネスに活用するデータサイエンティストの需要も高まっており、各企業では、データサイエンティストの育成に力を入れたり、高額な給与で採用したりと、人材不足に対応する動きが盛んになってきています。 データサイエンティストに欠かせないスキルの1つが、データ分析、ディープラーニング、機械学習などに必要となるプログラミングのスキルです。その中でも、Python(パイソン)に関する知識は必要不可欠となります。 Python(パイソン)は、直観的で非常にわかりやすいプログラミング言語で、シンプルに記述することができ、初心者でも大変学びやすい言語です。 また、たくさんのライブラリと呼ばれる再利用可能なプログラムが公開されていて、これらのライブラリを使って、比較的簡単に高度な機能を実現することができます。AIに関連するライブラリも数多くあり、機械学習、ディーブラーニングやデータ分析の分野でも広く使われています。 Pythonの開発環境だけで無く、これらの非常に便利なライブラリがインターネット上で無料で提供されており、費用をかけずに始めることができます。 この本では、今後データサイエンスや機械学習、AIを学習していきたいと考えている方へ向けて、それらの知識の習得に欠かせないPythonの基本的なトピックに重点を絞り、チュートリアル形式で解説していきます。プログラミング未経験者や初心者でもわかりやすいよう、丁寧に解説していきます。特にPythonでデータ分析・AI・機械学習を学ぶ上で欠かせない基礎となる重要な事項を取り上げています。 【 目次 】 第1章. 環境準備 この章では、Pythonを始めるにあたって欠かすことのできない、環境構築の方法について、初心者でもわかりやすいよう、1つ1つの手順を追って、丁寧に説明しています。是非この記事を元にPythonの開発環境を準備し、プログラミングにチャレンジしてください。 第2章. 基本操作 第1章で準備した開発環境について、今後の章の理解に必要となる基本的な操作の説明をしています。 第3章. 変数 最初に基本となるPythonの変数の宣言や変数名のルールを説明しています。変数とは何か?という説明から、具体的な例を用いて使い方の説明など、初心者にもわかりやすいよう丁寧な解説を心がけています。 第4章. データ型 次にPythonに用意されているデータ型の種類とその確認方法を説明しています。 第5章. 数値計算(四則演算) Pythonでは、数値は四則演算を行うことができるように演算子が用意されています。Pythonに用意されている基本的な四則演算を行うための演算子を確認していきましょう。 第6章. Print関数 画面にメッセージを表示したり、記述したプログラムが正常に動作するか確認する際に、変数などに格納された値を画面に出力するのに必要なprint関数についての解説です。 第7章. リスト(List) Pythonにおけるリスト(配列)の使い方に関する記事です。リストとは何か?その特徴は?という基本的な説明から始まり、リストへの要素の追加の方法や、追加した要素の変更、削除方法、また検索方法について説明しています。 第8章. タプル(Tuple) タプルは読み取り専用のリストのようなものです。タプルについても定義の仕方や検索方法について解説していきます。 第9章. ディクショナリ(Dictionary) Pythonには、キーと紐付けて値を登録することで、取り出しやすいかたちでデータを格納することができるDictionary(辞書)というものがあり、特徴や使い方を取り上げています。 第10章. 条件分岐(IF文) この章では、Pythonにおける条件分岐(If文)の記述方法や注意点について見ていきます。 第11章. 繰り返し処理(For文) Pythonの繰り返し処理の1つであるFor文の書き方や使い方の例を取り上げています。 第12章. 繰り返し処理(While文) Pythonの繰り返し処理にはWhile文もあり、For文との違いやWhile文の使い方を説明しています。 第13章. コメント プログラムに関する注釈であるコメントについての書き方や、規約・ルールの例、便利な表示方法について解説しています。 第14章. 関数 何度も繰り返し利用する処理は、関数と呼ばれる一連の命令として定義しておくと、同じコードを記述する必要が無く、関数を呼び出すだけで良いので非常に便利です。ここでは、関数の記述方法や呼び出し方について説明しています。 第15章. モジュール、パッケージ、ライブラリ Pythonでは、科学技術計算でよく使われるNumPy(ナンパイ)やグラフ描画に使われるMatplotlib(マットプロットリブ)、データ解析を支援する機能を提供するPandas(パンダス)など、多くの便利な機能がライブラリという形で提供されます。これらのインストール方法や利用するのに必要な基礎知識について説明しています。 第16章. NumPyでベクトル・行列計算 NumPy(ナンパイ)は、ベクトルや行列などを効率的に数値計算するための数学関数ライブラリを提供します。ここでは次のようなトピックについて解説していきます。 ・NumPyでのベクトル、行列の作成方法 ・連続した配列の自動作成 ・ランダムな数値を含む配列の自動作成 ・NumPyでの行列の計算方法 ・NumPyでの配列のインデックス ・NumPyでの配列の更新 ・NumPyの数値計算用関数 ・whereで条件に応じたデータを抽出 ・NumPyでのファイル操作関数 第17章. Matplotlibでグラフの描画 Pythonのグラフの描画に欠かせないのが、Matplotlib(マットプロットリブ)になります。Matplotlibは、Pythonのグラフ描画用ライブラリで、様々なグラフを作成し、データを可視化することができます。この章では、Matplotlibで折れ線グラフ、棒グラフ、円グラフ、散布図など各種グラフの描画方法を解説していきます。 [文字数 / ページ数] 約38,000 / 約200ページ [著者紹介] 清水 義孝 (しみず・よしたか) データサイエンティスト 1973年生まれ。 小学生の頃からプログラミングに興味を持ち、MSXでベーシックを習得し、ゲームの自作に夢中になる。 大学卒業後は、某大手IT企業でシステムエンジニアとして、数々のデータウェアハウス、データ分析基盤の導入に携わる。その中で、データ分析に興味を持ち始め、データ分析には、ITの知識、スキルだけでなく、ビジネスに関する深い知識やスキルが必要だと感じる。 論理・仮説思考力、統計・定量分析、プレゼンなどのスキル、ファイナンス・マーケティングなどのビジネスの知識を習得すべく、海外のビジネススクールに通いMBA(経営学修士)取得。 その後、某大手製造業でデータサイエンティストとして、ビックデータの分析に携わる。 データ分析、プログラミングに関して、初心者に役立つ情報を発信すべく、2018年よりWebサイト「Pythonで学ぶデータ分析・AI・機械学習」( https://ai-inter1.com/ )の運営を始める。 |

|

|

本書の内容
◆◆マウス操作だけで機械学習を体験◆◆
本書は「機械学習でできること」と「その方法」を、とことん平易に説明します。 普通なら高度な数学の知識を必要としますが、 本書では、ほぼ中学校で習うレベルで解説しますので、 一般ビジネスマンや文系の学生さんも安心して読めます。 「説明して終わり」ではありません。 「機械学習の組み立てキット」とでも呼ぶべきマイクロソフトのクラウドサービス 「ML Studio(Azure Machine Learning Studio)」を使い、 自分で機械学習の仕組みを作り、動かすところまでを体験します。 さらに、RやPythonによる高度活用など、中級以上の実務家にも役立つ情報を、 経験豊富な技術者集団が提供します。 ◆◆進化と広がりをキャッチアップ◆◆ 初版の刊行から4年を経て、機械は人間を超える精度で物体を識別できるようになりました。 ロボットやドローン、IoTと機械学習の融合が進展する一方、機械翻訳が実用化され、 音声通訳やAIスピーカーが家庭に普及。 もちろん、Azureの機械学習サービスも大きく拡充されています。 今回の改訂では、最新版のML StudioやR、Python、Visual Studioに対応するとともに、 近年ニーズが高まっている「異常検知」のために1章を書き下ろしました。 【目次】 第1章 イントロダクション 1.1 身近になった機械学習 1.2 Azure Machine Learning Studio とは? 1.3 ML Studio で機械学習を学ぶメリット 第2章 ML Studio を利用するための準備 2.1 Microsoft アカウントの取得 2.2 ML Studio の利用登録 2.3 ML Studio の起動と基本操作 第3章 機械学習で実現できること 3.1 6 つの用途 3.2 回帰 3.3 クラス分類 3.4 クラスタリング 3.5 情報圧縮 3.6 異常検知 3.7 レコメンデーション 第4章 実践! 回帰による数値予測 4.1 試してみよう 4.2 精度を評価しよう 4.3 精度を向上させよう 4.4 その他の手法 第5章 実践! クラス分類 5.1 試してみよう 5.2 精度を評価しよう 5.3 精度を向上させよう 5.4 その他の手法 第6章 実践! クラスタリング 6.1 試してみよう 6.2 結果を評価しよう 第7章 実践! 異常検知 7.1 試してみよう 7.2 結果を評価しよう 7.3 精度を向上させよう 第8章 実践! レコメンデーション 8.1 試してみよう 8.2 精度を評価しよう 8.3 精度を向上させよう 8.4 レコメンデーションを実用する前に 第9章 インターネットへの公開 9.1 自作モデルをWeb サービス化しよう 9.2 外部からアクセス可能にしよう 9.3 C# によるアクセス 9.4 R 言語によるアクセス 9.5 Python によるアクセス Appendix 付録 A.1 ML Studio 上でのR やPython による処理記述 A.2 統計解析ツールR のインストール A.3 Visual Studio のセットアップ |

|

|

本書の内容
機械学習アルゴリズムの違いが見てわかる!
「機械学習アルゴリズムは種類が多く、複雑で何をしているのかわかりにくい」と思ったこと、ありませんか?本書は、そのような機械学習アルゴリズムをオールカラーの図を用いて解説した機械学習の入門書です。 いままで複雑でわかりにくかった機械学習アルゴリズムを図解し、わかりやすく解説しています。アルゴリズムごとに項目を立てているので、どのアルゴリズムがどのような仕組みで動いているのか比較をしやすくしています。 これから機械学習を勉強する方だけでなく、実際に機械学習を業務で使用している方にも新しい気付きを得られるのでお勧めの1冊です。 【本書の特徴】 ・複雑な機械学習アルゴリズムの仕組みを1冊で学べる ・オールカラーの図をたくさん掲載 ・各アルゴリズム毎にScikit-Learnを使用したコードを記載しているので、見るだけでなく試すこともできる ・仕組みだけでなく、実際の使い方や注意点もわかる 【本書で紹介するアルゴリズム】 01 線形回帰 02 正則化 03 ロジスティック回帰 04 サポートベクトルマシン 05 サポートベクトルマシン(カーネル法) 06 ナイーブベイズ 07 ランダムフォレスト 08 ニューラルネットワーク 09 kNN 10 PCA 11 LSA 12 NMF 13 LDA 14 k-means 15 混合ガウス 16 LLE 17 t-SNE |
本書の内容
はじめに
この度は、「Python + LINEで作る人工知能開発入門 - Flask + LINE Messaging APIでの人工知能LINEボットの作り方 」を手に取っていただきまして、誠にありがとうございます。 本書はPythonというプログラミング言語を使って人工知能を使ったLINEボットの開発を始めたい人を対象に基礎的な内容をまとめたものです。 この内容は筆者がPythonを使って試行錯誤した成果をまとめたものです。 本書ではPythonのFlaskというフレームワークをサーバーサイドにして、GoogleのVision APIというサービスを呼び出すことでGoogleの人工知能を間接的に利用して、面白いLINEボットを作成するための基礎的なノウハウをまとめています。 この本を通じて実用段階にある人工知能のレベルとはどのようなものか?どんなことができるのか?ということが体験できると考えています。 また、LINEボットの開発に挑戦したいと考えている場合にも適していると思います。 本書はリフロー型のKindle電子書籍のフォーマットを採用しています。 一般的な紙の本とは異なる装丁を採用しているため、Kindle本をあまり利用されたことのない方は事前に「無料サンプルを送信する」の機能を利用して、確認をお願いします。 目次 1. AIと絡めた本書の内容の説明 1.1 AIとは何か? 1.2 人工知能アプリを作ることは本当に難しいのか? 1.3 機械学習APIを使用するという提案 1.4 LINEボットと人工知能の組み合わせ 1.5 なぜPythonを使用するのか? 1.6 本書の流れ 2. Python 2.1 Python2とPython3 2.2 Pythonの基本的な取り扱い 2.3 Pythonの基本文法 2.4 venv 3. LINE Botのバックエンドを構築するための下準備 - Flaskの基本 3.1 なぜLINE Botでバックエンドを構築する必要があるのか? 3.2 なぜLINE BotのバックエンドにFlaskを使用するのか? 3.3 Flaskの特徴 3.4 Flaskの導入 3.5 Flaskの基本的なルール 3.6 ルーティング 3.7 URLの基本構造 ~ Webアプリケーションの場合 3.8 リクエスト 3.9 Flaskでのログの扱い 3.10 FlaskでのJSONの取り扱い 4. Herokuを使用したFlaskのデプロイ 4.1 Herokuとは? 4.2 Herokuのアカウントを取得する 4.3 Herokuのコマンドラインツールを導入する 4.4 コマンドラインツールを使ってHerokuにログインする 4.5 HerokuでFlaskのアプリケーションをデプロイ 5. LINEボットの作り方 5.1 LINEの開発者アカウントを作成する 5.2 プロバイダーを作成する 5.3 チャネルを作成する 5.4 LINE BOTでHello World 5.5 Flaskでバックエンドサーバーを構築する - Messaging API SDKでWebhookサーバーを実装 5.6 LINE Botでユーザーから送信されたコンテンツを取得 6. Google Cloud Vision APIとの連携 6.1 Google Cloudの導入 6.2 Google Cloud Vision APIの登録を行う 6.3 文字認識(OCR)の機能を呼び出して文字起こしボットを作成する 6.4 顔検出の機能を呼び出してプライバシー保護Botを作成する 6.5 オリジナルのLINE Botを作ってみよう コードが動かないなどのトラブルシューティングについて 基本的に本書で記載しているOSなどの環境上で手順に従えばコードが動作することをすベて確認しています。 万が一、コードが動かなかった場合はエラーが発生する条件を再現できるよう必ず以下の情報をすベて併記した上で筆者にダイレクトメッセージを送ってください。 * エラーが発生したソースコード全体 * ソースコードに対応する本のページ番号や章番号 * OSの種類とバージョン(WindowsかMacOSかLinux、そしてそのバージョン) * プログラミング言語のバージョン(Python3.6かPython3.7) * フレームワークやパッケージのバージョン GitHubなどにエラーが発生したソースコード一式を公開していただけばエラーがどのような条件で実際に発生するかを再現・検証できるため、できる限り協力をお願いします。 以上の情報抜きで単純に「動かなかった!」などの詳細情報を省いた短いコメントを投稿されても、どのような条件でエラーが発生するのか検証できず、筆者側のミスか単なる勘違いかも分からず、また返信などのサポートもできないため控えていただくように重ねてお願い申し上げます。 |

本書の内容
AIのブラックボックスを開けよう!
ディープラーニングの本質を理解するために必要な「数学」を 「最短コース」で学べます! 本書では、ディープラーニングの理解には欠かせない数学を 高校1年生レベルから、やさしく解説します。 (微分、ベクトル、行列、確率など) 最短コースで理解できるように、 解説する数学の分野は必要最低限のものだけに絞り、 その相関関係を★特製の綴込マップ★にまとめました。 また、数学を使ってイチから記述したコードを Jupyter Notebook形式で提供しますので 実際に動かしながら学ぶことができます。 「ディープラーニング」の動作原理を「本当に」理解できる本です。 【導入編】 1章 機械学習入門 【理論編】 2章 微分・積分 3章 ベクトル・行列 4章 多変数関数の微分 5章 指数関数・対数関数 6章 確率・統計 【実践編】 7章 線形回帰モデル(回帰) 8章 ロジスティック回帰モデル(2値分類) 9章 ロジスティック回帰モデル(多値分類) 10章 ディープラーニングモデル 【発展編】 11章 実用的なディープラーニングを目指して ★巻頭綴じ込み★最短コースマップ |

|

本書の内容
ビジネスの現場で活用するための最短コースです!
本書は野村総合研究所のシステムコンサルティング事業本部で実施している 「アナリティクス研修」をベースにした書籍で、 「統計的なモデリングとは何か?」 「モデルに基づく要因の分析と予測の違いとは?」 「具体的なモデルの作り方」 「結果を解釈する際の落とし穴の見分け方」 など、ビジネスの現場感を重視した構成です。 実務で遭遇するデータ品質や加工のポイント、さらにRとPythonを利用し、 データからモデルを作成して結果を得るという基本的な手順を体験できます。 これからデータ分析や統計解析、機械学習を学び、現場でそれらを活用したい方に最短学習コースでお届けします。 |
本書の内容
必須のPython機械学習ライブラリを使いこなそう!
基本的な考え方からはじめ、80を超える手法を レシピとして網羅的に解説。 原著 2nd Edition待望の翻訳! scikit-learnは、機械学習を行うためのPythonライブラリです。 本書では、以下のscikit-learnのテクニックを解説しています。 ●機械学習の基本的な枠組み…NumPyの基本、データロード、可視化、SVM分類、 分類と回帰、交差検証 ●モデル構築前のワークフローと前処理…データ生成、正規分布化、二値特徴量化、 カテゴリ値操作、欠損値の補完、パイプライン化、ガウス過程、確率的勾配降下法 ●次元削減…PCA、因子分析、カーネルPCA、特異値分解、t-SNE、パイプライン化 ●線形モデルの構築…直線の適合、線形回帰モデル、リッジ回帰、パラメータ最適化、 正則化、LARS ●ロジスティック回帰…データのロード/可視化、ロジスティック回帰の誤分類/ 分類しきい値、ROC分析、ROC曲線、パイプライン化 ●距離指標によるモデル構築…k-means法、クラスタの評価、ミニバッチk-means法、 画像量子化、最近傍の特定、確率的クラスタリング、k-meansによる外れ値検出/回帰 ●交差検証とモデル構築後のワークフロー…交差検証によるモデル選択、k分割交差検証、 均衡な交差検証、ShuffleSplit、時系列交差検証、グリッドサーチ、分類指標、回帰指標、 クラスタリング指標、ダミー推定器、特徴選択、L1ノルム、モデル永続化 ●サポートベクトルマシン…線形SVMによるデータの分類、SVMの最適化、 SVMによる多クラス分類、サポートベクトル回帰 ●決定木とアンサンブル学習…決定木による分類、決定木の可視化、 決定木の調整、決定木による回帰、交差検定による過学習の抑制、 ランダムフォレスト回帰、最近傍法によるバギング回帰、勾配ブースティング決定木、 アダブースト回帰器の調整、スタッキングアグリゲータ ●テキストと多分類…確率的勾配降下法、ナイーブベイズ、ラベル伝播 ●ニューラルネットワーク…パーセプトロン分類器、多層パーセプトロン、 スタッキング ●単純な評価器の作成 ※本書は『scikit-learn Cookbook - Second Edition』の翻訳書です。 ※本書の対象読者として、データ分析のPythonプログラミングについて ある程度知識または経験のある方を想定しています。 |

本書の内容
本書は、機械学習モデルの性能を向上させるために、データから良い特徴量を作る特徴量エンジニアリングについて解説します。
前半では初学者に向けて、数値、テキスト、カテゴリ変数の基本的な取り扱い方を説明し、後半では特徴量ハッシング、ビンカウンティング、PCAによるデータの圧縮、さらに非線形特徴量とモデルスタッキング、画像特徴量抽出と深層学習による自動特徴学習などの高度なテーマを扱います。 特徴量エンジニアリングの原理について直感的な理解が得られるように図や例を豊富に使い、またPythonコードによる実行例を数多くあげて解説しており、実際の業務に適用するための具体的な知識が得られます。 特徴量エンジニアリングを使いこなし、機械学習モデルの性能を最大限に引き出したいエンジニア必携の一冊です。 Kaggle GrandmasterのKohei Ozaki(@smly)氏による「日本語版に寄せて」を収録しています。 |
本書の内容
Pythonデータ分析+機械学習への第一歩! 本格学習の前に、基礎を固め、全容を把握。― データの取り込み・整備・集約から、可視化、モデル化、正規化、高速化など、一連の基本作法を学べます。付録では、Python環境のインストール、Pythonの文法などを確認できます。使用するライブラリは、pandasを中心に、matplotlib、seaborn、numpy、statsmodels、sklearnなど。本書は『Pandas for Everyone: Python Data Analysis』の翻訳書です。
※この商品は固定レイアウトで作成されており、タブレットなど大きいディスプレイを備えた端末で読むことに適しています。また、文字列のハイライトや検索、辞書の参照、引用などの機能が使用できません。 購入前にお使いの端末で無料サンプルをお試しください。 |

|

本書の内容本書は、Pythonでプログラミングをした経験のある読者が、 またその中で、自然言語処理に関連するさまざまな概念や手法、 本書の構成としては大きく2つの部に分かれており、 第1部:データの準備 第2部:データの解析 全13章を順に追いながらWebアプリケーションを作っていくことで、 ※本電子書籍は同名出版物を底本として作成しました。記載内容は印刷出版当時のものです。 |

本書の内容
・WindowsでPython開発が手軽にできるツールを使い、AIプログラミングを体験する本です。
・人工知能の学習テーマとして、再帰処理、ゲームAI、推論エンジン、機械学習、ディープラーニングなど、バラエティに富んだ内容とプログラミング・ノウハウを解説します。 ・以下の開発環境、パッケージ、フレームワークを使用します。 PyScripter … 導入と操作が簡単な開発環境 Pygame … グラフィックスの記述が簡潔にできる Keras … 機械学習、ディープラーニングの記述が簡潔にできる サンプルプログラムの提供 ・全ソースコードはWebからダウンロードでき、すべて無償ツールを使ってすぐに動かすことができます。 本書の特徴 ・幅広いテーマの人工知能プログラミング体験 ・オブジェクト指向の活用による効率良い発展的な開発。 ・関数型スタイルを取り入れて関数型プログラミングセンスを養う。 ・グラフィックスとマルチスレッドの活用による動きのある実体験。 ・難しい数理的理論表現を避け、豊富な図解とサンプルによる具体例。 本書では、Pythonを使った以下のような実践により、人工知能のみならずPythonの活用法やプログラミングの広範囲なスキルに触れることができます。 ・関数型スタイル、再帰関数、ラムダ式、連結リスト処理、メソッドチェーン ・オブジェクト指向、クラス、派生、オーバーライド ・マルチスレッディング、ゲーム速度制御 ・グラフィックス処理(Pygame、Matplotlib) ・配列処理、キュー処理、連想配列処理 ・キー入力処理、マウス入力処理 ・トレース処理、状態遷移図 ・機械学習・ディープラーニング(Keras)、モデル・特徴マップ・重みの可視化 ・GPU(CUDA、cuDNN)による学習処理の高速化 |

本書の内容
Pythonを始めたからには、やっぱり機械学習でしょう。ほとんどの書籍が、機械学習を取り上げています。
機械学習とは、「未知の問題に対して、正しい答えが導き出せるように学習させること」と、定義したとき、大きな問題にぶつかります。 どうやって学習させるか。これは、Pythonが解決してくれます。機械学習については、非常に構造化されていますから、例えば、教師あり学習の場合、わずか2行のプログラムで学習させることができます。 では、大きな問題とは? どの計算式を使えば良いかの選択です。これができない限り、機械学習に取り組むのは危険です。 かといって、機械学習の専門書に記述されているような計算式を理解するのは専門家でもない限り、ほぼ、無理といっていいでしょう。 そこで、この本では、手書き数字認識、アヤメの分類を題材として、プログラムを完成させるまでの手順、数式を理解できないが故に、行って欲しい手順を主に構成しています。 プログラムは、非常に構造化されているお陰で、公式的なものがほとんどです。教師あり学習については、ここで、記述したプログラムを少し修正するだけで、他でも使用できると思います。 Chapter1 事前の準備 §1 認識させたい画像の準備 5 Chapter2 機械学習につて §1 機械学習とは 6 §2 学習用画像を用意する 7 §3 画像を表示してみる 9 §4 何の数字のデータか表示する 12 §5 生データを取得する 13 Chapter3 学習する §1 教師用(学習用)データを切り取る 14 §2 学習用プログラム 17 §3 正解と予測値を表示する 21 §4 間違えた要因を考えてみる 23 §5 ベストなCとgammaを設定する 24 §6 学習結果の保存 28 Chapter4 実画像の判定 §1 画像フォーマットの変換 30 §2 判定します 33 Chapter5 機械学習モデルについて §1 k-最近傍法 34 §2 線形モデル 38 §3 サポートベクタマシン(SVM) 40 §4 決定木 42 §5 決定木のチューニング 45 Chapter6 ベストな学習器を選択する §1 交差検証 47 Chapter7 アヤメの分類 §1 データ構造を調べる 50 §2 学習する 54 §3 すべての分類器を試してみる 55 まとめ |
本書の内容
※このKindle本はプリント・レプリカ形式で、Kindle Paperwhiteなどの電子書籍リーダーおよびKindle Cloud Readerではご利用いただけません。Fireなどの大きいディスプレイを備えたタブレット端末や、Kindle無料アプリ (Kindle for iOS、Kindle for Android、Kindle for PC、Kindle for Mac) でのみご利用可能です。また、文字列のハイライト、検索、辞書の参照、引用については、一部機能しない場合があります。文字だけを拡大することはできません。
※プリント・レプリカ形式は見開き表示ができません。 ※この電子書籍は紙版書籍のページデザインで制作した固定レイアウトです。 Pythonでデータサイエンスの理論と実践を学ぶ データサイエンスは、「データを科学的に扱う」学問分野であり、近年、ICTの進展によって、センサやインターネットを通じて取得できるデータ量が爆発的に増加したこと、コンピュータの高性能化に伴ってこれまでできなかった大規模なデータ処理が可能となったことなどから注目されています。 本書は、データサイエンスの意味から金融データの分析、動的システムの分析などの工学応用までを、Pythonを使って実際に分析しながら学ぶものです.データの取り扱い、確率・統計の基礎といった基本的なところから、回帰分析、パターン認識、深層学習といった統計・機械学習手法、金融データなど時々刻々と変化する時系列データの分析、センサデータなどに含まれるノイズや外乱を見極めるスペクトル分析、さらにこのノイズや外乱を除去するためのディジタルフィルタ、そして最後に画像データの分析として画像処理の解説を行い、読者がデータサイエンスの一通りを俯瞰できるようになっています。 Pythonを使った解説によって理論と実践を同時に学ぶことができるので、データサイエンスを学び、自身の分野に応用したい方にピッタリの一冊です。 1章 はじめに 2章 データの扱いと可視化 3章 確率の基礎 4章 統計の基礎 5章 回帰分析 6章 パターン認識 7章 深層学習(ディープラーニング) 8章 時系列データ分析 9章 スペクトル分析 10章 ディジタルフィルタ 11章 画像処理 おわりに 参考文献 |

本書の内容
強化学習が実装できる! エンジニアのために、Pythonのサンプルコードとともに、ゼロからていねいに解説。実用でのネックとなる強化学習の弱点とその克服方法、さらに活用領域まで紹介した。コードも公開!
・Pythonプログラミングとともに、ゼロからていねいに解説。 ・コードが公開されているから、すぐ実践できる。 ・実用でのネックとなる強化学習の弱点と、その克服方法まで紹介。 【おもな内容】 Day1 強化学習の位置づけを知る Day2 強化学習の解法(1): 環境から計画を立てる 価値の定義と算出: Bellman Equation 動的計画法による状態評価の学習: Value Iteration 動的計画法による戦略の学習: Policy Iteration モデルベースとモデルフリーとの違い Day3 強化学習の解法(2): 経験から計画を立てる 経験の蓄積と活用のバランス: Epsilon-Greedy法 計画の修正を実績から行うか、予測で行うか: Monte Carlo vs Temporal Difference 経験を状態評価、戦略どちらの更新に利用するか Day4 強化学習に対するニューラルネットワークの適用 強化学習にニューラルネットワークを適用する 状態評価を、パラメーターを持った関数で実装する: Value Function Approximation 状態評価に深層学習を適用する: Deep Q-Network 戦略を、パラメーターを持った関数で実装する: Policy Gradient 戦略に深層学習を適用する: Advantage Actor Critic(A2C) 状態評価か、戦略か Day5 強化学習の弱点 サンプル効率が悪い 局所最適な行動に陥る、過学習をすることが多い 再現性が低い 弱点を前提とした対応策 Day6 強化学習の弱点を克服するための手法 サンプル効率の悪さへの対応:モデルベースとの併用/表現学習 再現性の低さへの対応:進化戦略 局所最適な行動/過学習への対応:模倣学習/逆強化学習 Day7 強化学習の活用領域 |
|
発売日 2019/01/12
本書の内容 |

|

本書の内容
本書は、機械学習を手軽に学習し、さらにそれを活用するために、実践的なPythonのサンプルコードを使って紹介しています。
最近では、深層学習の活用はさまざまな分野に広がっています。2000 万件もの医学論文を学習した人工知能のWatsonが、専門の医師でも診断が難しい特殊な白血病を10 分ほどで見抜き、治療法を変えるよう提案した結果、女性患者の命が救われたというニュースもありました。 このような機械学習の成功例に関するニュースを聞くと、ぜひ、自分の業務でも、活用してみたいと思うのは自然なことです。 実際のところ、データを活用する際に、難しい数式を意識する必要はそれほどありません。利用したいデータさえ手元にあれば、本書に掲載されているプログラムをちょっと改良するだけで、自分が求めている処理を実現することができることでしょう。 本書は、2016 年に発売され好評だった『Pythonによるスクレイピング&機械学習開発テクニック』を大幅に改訂したものです。最先端の機械学習(特に、深層学習)の分野にあって、2、3 年というのは決して短くない時間です。ですから、当時主流だった方法が時代遅れになっていたり、ライブラリに大きなバージョンアップがあったりするのは仕方のないことでしょう。そこで、本書では、全面的にソースコードを修正し、非推奨となったライブラリを捨て、新しいライブラリやフレームワークの解説を追加しました。また、ここ数年で、WebサイトのHTTPS化が加速したので、その点も踏まえて、全面的に修正しています。 |